

Beautiful Soup と Requestsを使用した基本的なスクレイピングについて紹介します。
【Python】スクレイピングとは
スクレイピングとは、プログラムを使用してウェブページからデータを自動的に収集する技術のことを指します。通常、ウェブページはHTMLとしてブラウザに表示されますが、スクレイピングではそのHTMLからテキストや画像、リンクなどのデータを抽出し、任意の形式に整理して保存します。
スクレイピングの用途
スクレイピングの主な用途には、次のようなものがあります。
- 価格の比較
eコマースサイトから商品価格を収集し、他サイトと比較する。 - ニュースやSNSのモニタリング
ニュースサイトやSNSから最新のトピックや記事を収集し、分析に役立てる。 - 研究データの収集
研究目的で公開データを収集し、統計分析やマーケットリサーチに利用する。 - 不動産情報の収集
不動産サイトから物件情報を自動収集し、一覧表に整理する。
スクレイピングとAPIの違い
スクレイピングは、主にウェブページのHTMLを解析してデータを取得する手法です。
一方、API(アプリケーション・プログラミング・インターフェース)を利用したデータ取得は、提供者が公式に提供するインターフェースから直接データを引き出します。
APIはアクセス制限が設けられていることが多く、規制されたデータのみが提供される一方で、スクレイピングは理論上公開されている情報なら制限なく取得できます。
スクレイピングの注意点
スクレイピングは合法ですが、注意が必要です。特に、以下の点には注意する必要があります。
- 利用規約の遵守
多くのサイトがスクレイピングを禁止している場合がある為、利用規約を確認することが重要です。 - 適切なアクセス頻度
サーバーに負担をかけないよう、短時間に大量のリクエストを送ることは避ける必要があります。 - 著作権やプライバシーの配慮
取得したデータの使用方法は、著作権やプライバシーに関する法律に準拠する必要があります。

【Python】Beautiful Soup と Requests によるスクレイピングの実行
スクレイピング実行環境
- OS
- Windows 10 Pro 22H2
- OSビルド:19045.5011
- コードエディタ(IDE)
- Visual Studio Code Ver. 1.94
※仮想環境(v_scraping)を作成して実行しています。
- Visual Studio Code Ver. 1.94
- Python:Ver. 3.10.11
スクレイピングに必要なライブラリ
Pythonでスクレイピングに最もよく使用されているライブラリとして、以下の3つが挙げられます。
①Beautiful Soup
- 概要
Beautiful SoupはHTMLやXMLの解析を容易にするためのライブラリです。HTMLドキュメントをツリー構造に変換し、タグや属性を指定してデータを抽出しやすくします。 - 特徴
タグやクラスを指定してデータを簡単に取得できるため、初心者でも扱い易く、lxmlやhtml.parserといったパーサーと組み合わせて使用され、HTMLが多少壊れていても正確に解析できます。 - 用途例
ニュースサイトのタイトルや本文、製品情報ページからの商品名や価格の取得など。
②Requests
- 概要
Requestsは、HTTPリクエストを送信し、サーバーからデータを取得するためのライブラリです。シンプルな構文でGETやPOSTなどのリクエストを簡単に行えます。 - 特徴
認証やクッキーの管理、ヘッダー設定などが簡単に行えます。
Beautiful Soupやlxmlと一緒に使用されることが多く、ページのHTMLを取得するための基盤として活用されます。 - 用途例
APIへのリクエスト送信や、ウェブページからHTMLを取得する際に使用。
③Selenium
- 概要
Seleniumは、ブラウザ操作を自動化する為のライブラリで、動的に生成されるコンテンツのスクレイピングに適しています。JavaScriptによって表示される要素も取得できる為、通常のスクレイピングでは難しい動的ページにも対応できます。 - 特徴
ChromeやFirefox等のブラウザを起動して操作できる為、動的コンテンツのレンダリングも可能です。構成が複雑で実行速度が遅くなることもありますが、JavaScriptの実行が必要なページには有効です。 - 用途例
商品サイトの詳細情報や、ボタン操作が必要なページのデータ取得など。
これらのライブラリは組み合わせて使われることも多く、特にBeautiful SoupとRequests、もしくはSeleniumとBeautiful Soupの組み合わせは定番です。

Beautiful Soup と Requests を使用したスクレイピング
Beautiful Soup と Requests を使用したスクレイピングのサンプルを紹介します。指定したウェブページからデータを取得して、解析し、欲しい情報を抽出します。
スクレイピングするWebページと、Webページの内容確認
Pytonの公式ダウンロードページ「https://www.python.org/downloads/」に掲載されているリリースの一覧表から「リリース番号」と「リリース日」のスクレイピングを考えてみます。
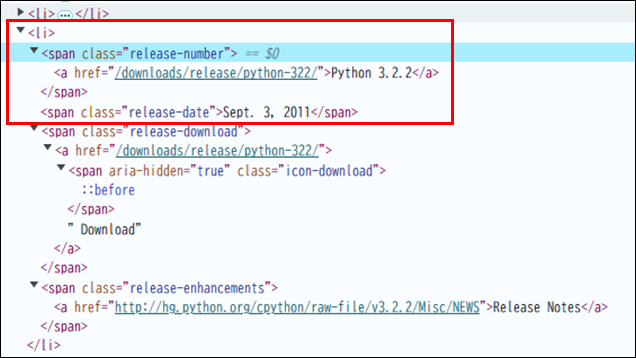
Webページの内容を確認すると、
- <li> 要素の中に<span>要素がある。
- class属性「release-number」がある<span>要素の中の、<a>要素の中にリリース番号が記載されている。
- class属性「release-date」がある<span>要素の中の、リリース日が記載されている。
その為、<li>要素を見つけclass属性が「release-number」の<span>要素から「リリース番号」を取得します。同じように、class属性が「release-date」の<span>要素から「リリース日」を取得できます。
スクレイピングの実施
①ターミナルで、必要なライブラリをインストールします。
pip install requests
pip install beautifulsoup4②スクレイピングするコードです。
Web上のデータを取得するには、get()関数を使用します。get()関数はレスポンスのオブジェクトを返します。オブジェクトからデータを取り出すには、「レスポンス.text」のようにして取り出します。
import requests
from bs4 import BeautifulSoup
# スクレイピングする対象のURL(pytonの公式ダウンロードページ)を指定
url = 'https://www.python.org/downloads/'
#1. RequestsでHTTPリクエストを送信しHTMLを取得
response = requests.get(url)
#2.ステータスコード200の確認(200は成功を意味します)
if response.status_code == 200:
# .textで取得したデータを格納するリスト
release = []
#3.Beautiful SoupでHTMLを解析
soup = BeautifulSoup(response.text, 'html.parser')
#4. <li>タグの検索
for li in soup.find_all('li'):
#5.li 要素内から、<span>タグで、class属性がrelease-numberとなっている要素の検索
if x := li.find('span', class_='release-number'):
#6. x 要素内から最初の <a> タグを検索
if y := x.find('a'):
#7. <span> タグで、class が ‘release-date’ の要素を検索
if z := li.find('span', class_='release-date'):
#8.リストreleaseに、「リリース番号」と「リリース日」を追加
release.append((y.text, z.text))
#9.リリース番号のソート
release.sort()
#最初に出力する際の改行
print()
#10.「リリース番号」と「リリース日」の取り出し
for name, date in release:
#11.「リリース番号」と「リリース日」の出力
print(f'{name:15}{date}')
コードの実行結果
実行結果は以下の様になります。
(v_scraping) PS C:\Python_Sample\01_scraping_01> c:; cd 'c:\Python_Sample\01_scraping_01'; & 'c:\Python_Sample\01_scraping_01\v_scraping\Scripts\python.exe' 'c:\Users\xxxxxxxxxx\.vscode\extensions\ms-python.debugpy-2024.12.0-win32-x64\bundled\libs\debugpy\adapter/../..\debugpy\launcher' '54116' '--' 'C:\Python_Sample\01_scraping_01\scraip_01.py'
bs\x5cdebugpy\x5cadapter/../..\x5cdebugpy\x5clauncher' '54116' '--' 'C:\x5cPython_Sample\x5c01_scraping_01\x5cscraip_01.py' ;191da820-b505-40f7-9e67-58069a4da2ae
Python 2.0.1 June 22, 2001
Python 2.1.3 April 9, 2002
Python 2.2.0 Dec. 21, 2001
Python 2.2.1 April 10, 2002
Python 2.2.2 Oct. 14, 2002
Python 2.2.3 May 30, 2003
Python 2.3.0 July 29, 2003
Python 2.3.1 Sept. 23, 2003
Python 2.3.2 Oct. 3, 2003
Python 2.3.3 Dec. 19, 2003
Python 2.3.4 May 27, 2004
Python 2.3.5 Feb. 8, 2005
Python 2.3.6 Nov. 1, 2006
Python 2.3.7 March 11, 2008
Python 2.4.0 Nov. 30, 2004
コードの詳細解説
1.RequestsによるHTTPリクエスト送信
response = requests.get(url)requests.get(url) によって、指定したURLのページにHTTPリクエストを送信し、ページのHTMLデータを取得します。この処理により、対象のページの内容が response変数に保存されます。
2.ステータスコードの確認
if response.status_code == 200:HTTPリクエストが成功すると、ステータスコード 200 が返されます。200 が返されている場合は次の解析処理に進み、それ以外の場合(例えば 404 や 500 )はページ取得に失敗したと判断できます。
3.Beautiful SoupによるHTML解析
soup = BeautifulSoup(response.text, 'html.parser')requests.get(url)で取得したWebページのレスポンス(文字列)を、html.parserを使用して取得したHTMLを解析し、操作やデータ抽出ができるようにBeautifulSoupオブジェクト(ここではsoup)に変換します
4.<li>タグの検索
for li in soup.find_all('li'):soupオブジェクトから全ての<li>タグを検索し、 条件に一致するすべての要素をリストとして返します。
5.class属性がrelease-numberとなっている要素を検索
if x := li.find('span', class_='release-number'):<li> 要素内から<span>タグで、class属性がrelease-numberとなっている要素を検索します。もしその要素が見つかれば、その要素「リリース番号」が返されますが、見つからなければ None が返ります。
6.x 要素内から最初の <a> タグを検索
if y := x.find('a'):x 要素内から最初の <a> タグを検索します。見つかればその <a> 要素が返され、見つからなければ None が返されます。
7.<span> タグで、class が ‘release-date’ の要素を検索します
if z := li.find('span', class_='release-date'):li 要素内から最初に見つかった <span> タグで、class が ‘release-date’ の要素を検索します。見つかればその <span> 要素「リリース日」が返され、見つからなければ None が返ります。
8.「リリース番号」と「リリース日」の追加
release.append((y.text, z.text))リストreleaseに、「リリース番号」と「リリース日」をタプルとして追加しています。
9.リリース番号のソート
release.sort()release はタプルのリストで、各タプルは(リリース番号, リリース日)の形式になっているため、リストは各タプルの最初の要素(リリース番号)を基準にアルファベット順でソートされます。
10.「リリース番号」と「リリース日」の取り出し
for name, date in releaserelease リストから順に各タプルを取り出し、name に「リリース番号」、date に「リリース日」を格納します。
11.「リリース番号」と「リリース日」の出力
print(f'{name:15}{date}')f 文字列で、「リリース番号」と「リリース日」 をフォーマットして出力します。「リリース番号」は、出力幅を15文字に設定されています。


