

SeleniumとBeautiful Soupを使用した基本的なスクレイピングについて紹介します。
【Python】スクレイピング
「スクレイピング」や、「スクレイピングの用途」「スクレイピングとAPIの違い」等、基本的事項は、下記のブログを参照してください。
参照ブログ:「Webスクレイピング Beautiful Soup & Requests」
【Python】スクレイピングの実行(Selenium&Beautiful Soup)
スクレイピング実行環境
- OS
- Windows 10 Pro 22H2
- OSビルド:19045.5011
- コードエディタ(IDE)
- Visual Studio Code Ver. 1.94
※仮想環境(v_scraping)を作成して実行しています。
- Visual Studio Code Ver. 1.94
- Python:Ver. 3.10.11
SeleniumとBeautiful Soupライブラリ
ライブラリの概要を以下に紹介します。
①Selenium
- 概要
Seleniumは、ブラウザ操作を自動化する為のライブラリで、動的に生成されるコンテンツのスクレイピングに適しています。JavaScriptによって表示される要素も取得できる為、通常のスクレイピングでは難しい動的ページにも対応できます。 - 特徴
ChromeやFirefox等のブラウザを起動して操作できる為、動的コンテンツのレンダリングも可能です。構成が複雑で実行速度が遅くなることもありますが、JavaScriptの実行が必要なページには有効です。 - 用途例
商品サイトの詳細情報や、ボタン操作が必要なページのデータ取得など。
②Beautiful Soup
- 概要
Beautiful SoupはHTMLやXMLの解析を容易にするためのライブラリです。HTMLドキュメントをツリー構造に変換し、タグや属性を指定してデータを抽出しやすくします。 - 特徴
タグやクラスを指定してデータを簡単に取得できるため、初心者でも扱い易く、lxmlやhtml.parserといったパーサーと組み合わせて使用され、HTMLが多少壊れていても正確に解析できます。 - 用途例
ニュースサイトのタイトルや本文、製品情報ページからの商品名や価格の取得など。
今回は、SeleniumとBeautiful Soupを組み合わせたスクレイピングを紹介します。

Selenium を使用する事の利点
Seleniumを使うとPythonや他のプログラミング言語から自動的にブラウザを操作できるので、次のようなことが可能になります。
- ページの動的な要素の読み込み
JavaScriptによって生成される動的な要素(例:動的なテーブル、チャート、ロード後に表示されるコンテンツなど)も、実際のブラウザと同じようにレンダリングされます。静的なHTMLでは取得できないコンテンツも、レンダリング後のDOMから取得することができます。 - ユーザー操作の自動化
ページのロードやレンダリング後に、リンクのクリック、フォームの入力、スクロールなどの操作も可能です。これにより、ユーザーが行う操作をシミュレートしながらデータを取得することができます。
Seleniumでのページレンダリングの一般的な流れ
「ページレンダリング」とは、Seleniumを用いてウェブページを実際にブラウザ上で開き、そのページのHTMLやCSS、JavaScriptを実行させることで、ユーザーが見た時と同じようにウェブページを表示させることを意味します。
- ブラウザの起動
SeleniumでWebDriver(ChromeDriverやGeckoDriverなど)を用いてブラウザを起動します。 - ページの読み込み
指定したURLを開き、ページがレンダリングされるのを待ちます。 - DOM操作や情報取得
ページが完全にレンダリングされた後、find_element や get_attributeなどのメソッドを使用して、必要な情報を取得します。 - ページ間の操作
ページ遷移やフォームの入力、ボタンのクリックなどを実行して、次のステップに進むことができます。
Seleniumを使ったページレンダリングは、特に動的コンテンツが多いウェブサイトや、JavaScriptで更新されるコンテンツを取得する際に非常に役立ちます。

SeleniumとBeautiful Soupを使用したスクレイピング
SeleniumとBeautiful Soupを使用したスクレイピングのサンプルを紹介します。指定したウェブページからデータを取得して、解析し、欲しい情報を抽出します。
スクレイピングするWebページと、Webページの内容確認
Pytonの公式ダウンロードページ「https://www.python.org/downloads/」に掲載されているリリースの一覧表から「リリース番号」と「リリース日」のスクレイピングを考えてみます。
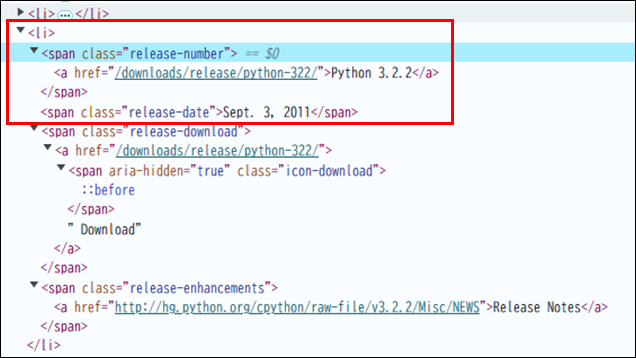
Webページの内容を確認すると、
- <li> 要素の中に<span>要素がある。
- class属性「release-number」がある<span>要素の中の、<a>要素の中にリリース番号が記載されている。
- class属性「release-date」がある<span>要素の中の、リリース日が記載されている。
その為、<li>要素を見つけclass属性が「release-number」の<span>要素から「リリース番号」を取得します。同じように、class属性が「release-date」の<span>要素から「リリース日」を取得できます。
スクレイピングの実施
①ターミナルで、必要なライブラリをインストールします。
Seleniumを使うには、まずWebドライバをインストールしておく必要があります。ここでは、Chromeを使う例を示しますが、他のブラウザでも構いません。
webdriver_managerパッケージを使うと、Seleniumが自動的にchromedriverをインストールしてくれるので便利です。
pip install selenium webdriver-manager
pip install selenium beautifulsoup4
pip install beautifulsoup4②スクレイピングするコードを下記に示します。
Web上のデータを取得するには、get()関数を使用します。get()関数はレスポンスのオブジェクトを返します。オブジェクトからデータを取り出すには、「レスポンス.text」のようにして取り出します。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Chromeドライバを自動でインストールし、ブラウザを起動する
service = Service(ChromeDriverManager().install())
# Seleniumの設定
options = webdriver.ChromeOptions()
options.add_argument('--headless') # ヘッドレスモードで実行する場合
driver = webdriver.Chrome(service=service, options=options)
# スクレイピングするURL
url = 'https://www.python.org/downloads/'
# 1. Seleniumでページにアクセス
driver.get(url)
# 指定した要素が読み込まれるまで待つ
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'release-number')))
# 3. Beautiful SoupでHTMLを解析
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 4. リストの初期化
release = []
# 5. <li> タグを検索
for li in soup.find_all('li'):
# 6. <span> タグで class が 'release-number' の要素を検索
if x := li.find('span', class_='release-number'):
# 7. 最初の <a> タグを検索
if y := x.find('a'):
# 8. <span> タグで class が 'release-date' の要素を検索
if z := li.find('span', class_='release-date'):
# 9. リスト release に「リリース番号」と「リリース日」を追加
release.append((y.text, z.text))
# 10. リリース番号のソート
release.sort()
# 改行を出力
print()
# 11. 「リリース番号」と「リリース日」の取り出しと出力
for name, date in release:
print(f'{name:15}{date}')
# Seleniumドライバを閉じる
driver.quit()

コードの詳細解説
ライブラリのインポート
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC- selenium.webdriver
Seleniumはウェブブラウザを自動操作するためのツールです。このコードでは、webdriverを使ってChromeブラウザを操作します。
- webdriver_manager.chrome
webdriver_managerはSelenium用のChromeドライバを自動的にインストールし、バージョン管理を簡単にします。
- selenium.webdriver.chrome.service.Service
Serviceクラスは、chromedriverのサービス設定を行います。
- selenium.webdriver.common.by.By
Seleniumで要素を探す際に、指定方法を設定するためのモジュールです(例: By.CLASS_NAME)。
- bs4.BeautifulSoup
Beautiful SoupはHTMLやXMLを解析するためのライブラリです。ここでは、Seleniumで取得したページソースを解析します。
- selenium.webdriver.support.ui.WebDriverWaitとselenium.webdriver.support.expected_conditions
WebDriverWaitはページの要素が出現するまで待機するのに使われます。expected_conditionsは、特定の条件が満たされるまで待機するための条件を定義します。
Chromeドライバの設定と起動
# 1.Chromeドライバのインストール
service = Service(ChromeDriverManager().install())
# 2.ヘッドレスモードの設定
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# 3.ブラウザの起動
driver = webdriver.Chrome(service=service, options=options)- 1.Chromeドライバのインストール
ChromeDriverManager().install()でドライバを自動的にインストールし、そのパスをServiceに渡します。
- 2.ヘッドレスモードの設定
webdriver.ChromeOptions()でChromeのオプションを設定しています。options.add_argument(‘–headless’)により、Chromeを画面上に表示せずにバックグラウンドで実行する「ヘッドレスモード」にしています。
- 3.ブラウザの起動
webdriver.Chrome(service=service, options=options)により、Chromeドライバが起動され、指定したオプションで動作するようになります。
ページへのアクセス
url = 'https://www.python.org/downloads/'
driver.get(url)driver.get(url)で指定したURLにアクセスします。この操作によって、SeleniumがChromeドライバを通してブラウザを開き、そのURLのページをロードします。
ページの読み込み待機
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'release-number')))ページが完全に読み込まれる前に次の処理をするとエラーになる可能性があるため、要素がページに現れるまで待機します。WebDriverWait(driver, 10)は、最大10秒間待機し、EC.presence_of_element_located((By.CLASS_NAME, ‘release-number’))が満たされるまで待機します。
Beautiful SoupでHTML解析
soup = BeautifulSoup(driver.page_source, 'html.parser')driver.page_sourceで現在のページのHTMLソースを取得し、Beautiful Soupで解析します。これにより、HTMLの構造を基に情報を抽出できます。
リストの初期化
release = []取得したデータを保存するための空リストreleaseを作成します。
データの抽出
# 1.<li>タグの検索
for li in soup.find_all('li'):
# 2.release-numberクラスを持つ<span>タグの検索
if x := li.find('span', class_='release-number'):
# 3.最初の<a>タグを取得
if y := x.find('a'):
# 5.リストへの追加
if z := li.find('span', class_='release-date'):
release.append((y.text, z.text))- 1.<li>タグの検索
soup.find_all(‘li’)で、ページ内のすべての<li>タグを検索します。各<li>タグに対して順に操作を行います。
- 2.release-numberクラスを持つ<span>タグの検索
li.find(‘span’, class_=’release-number’)で、classがrelease-numberの<span>タグを探します。
- 3.最初の<a>タグを取得
x.find(‘a’)で、上記の<span>内の最初の<a>タグを取得し、リンクテキスト(リリース番号)をy.textで抽出します。
- 4.release-dateクラスを持つ<span>タグの検索
li.find(‘span’, class_=’release-date’)で、リリース日が含まれるrelease-dateクラスの<span>タグを探します。
- 5.リストへの追加
release.append((y.text, z.text))で、リリース番号とリリース日をreleaseリストに追加します。
データのソートと出力
release.sort()
print()
for name, date in release:
print(f'{name:15}{date}')release.sort()でリスト内のリリース番号をアルファベット順にソートします。次に、各リリース番号とリリース日をprint()で出力します。f'{name:15}{date}’は、リリース番号を15文字分のスペースで揃えて表示します。
ドライバの終了
driver.quit()スクレイピングが終了したら、driver.quit()でChromeドライバを閉じ、リソースを解放します。


