

SQLエディタの強力な機能として「SQLを2回実行し結果セットを比較」があります。この機能がいかに便利で効率的な機能なのか紹介します。使用すると格段に作業効率が向上します。
本ブログでは以下の環境を使用します。実際に試される方は下記のブログを参照ください。
PostgreSQL(Ver 16.4) :PostgreSQLのインストール
A5M2(A5:SQL Mk-2)(Ver 2.19.2):A5M2(A5:SQL Mk-2)のインストール(Zip版)
外部データベース接続方法:【PostgreSQL】「pgAdmin4」外部データベースサーバーの接続方法
【A5M2(A5:SQL Mk-2)】『SQLを2回実行し結果セットを比較』
『SQLを2回実行し結果セットを比較』とは?
この機能はデータベースを操作する前と操作した後の結果比較を視覚的に確認できる機能です。そのため変更前の状態を取得する「1回目のSQL文」を実行し、変更後の状態を取得する「2回目のSQL文」を実行します。
それぞれの結果セットを比較することで、データの変化やクエリの結果の違いを視覚的に確認できます。例えば、在庫データを更新した後、その変更を視覚的に検証する場合に便利です。
比較結果は、差分(追加、削除、変更)として表示されます。
この機能が便利な点
- 差分が一目で分かる
テーブルやリスト形式で表示されるため、違いを視覚的に確認できる - 手作業での比較作業の軽減
大量のデータを目視で比較する手間を大幅に削減 - クエリロジックの検証
結果セットがどのように変化したかをすぐに確認できるため、クエリチューニングやデバッグが効率的に実行できる
どのような場面で役立つのか?
- データ更新後の検証
データ更新処理が正しく動作しているか確認できる - 異なるSQLの結果比較
ロジックを変えたクエリが正確に結果を返しているか検証できる - データ移行の整合性確認
古いデータベースと新しいデータベース間のデータ一移行の整合性を確認できる

実際の使用例:書籍在庫データの変更を比較
使用例の内容
ここでは書籍在庫テーブルを作成し書籍データや在庫数を変化させてデータの変更結果を確認します。
書籍在庫テーブルの作成
以下のSQL文を実行して「書籍在庫テーブル」を作成し、データを確認します。
-- 書籍情報テーブル
CREATE TABLE books (
book_id SERIAL PRIMARY KEY, -- 書籍ID(自動生成)
title VARCHAR(150) NOT NULL, -- 書籍名
author VARCHAR(100), -- 著者名
price NUMERIC(10, 2) NOT NULL, -- 価格
stock INT DEFAULT 0, -- 在庫数
created_at TIMESTAMP DEFAULT NOW() -- 作成日時
);
-- サンプルデータ挿入
INSERT INTO books (title, author, price, stock)
VALUES
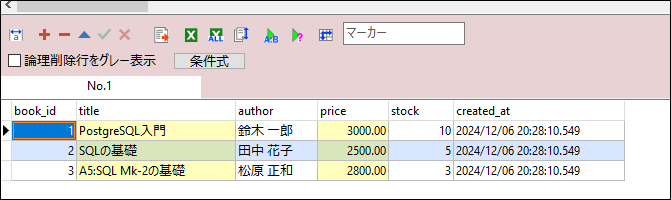
('PostgreSQL入門', '鈴木 一郎', 3000, 10),
('SQLの基礎', '田中 花子', 2500, 5),
('A5:SQL Mk-2の基礎', '松原 正和', 2800, 3);
-- データの表示
SELECT * FROM books;上記SQLの実行結果です。
1回目のSQLの実行
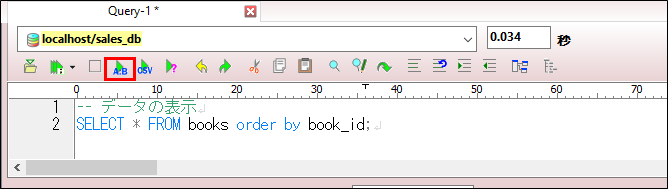
現在の状態でSQLエディタに1回目に実行するSQL文「SELECT * FROM books order by book_id;」を入力し、「A:B」ボタンをクリックします。
※order by book_idはプライマリキーなので省略可能。
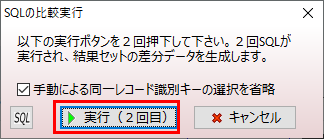
「手動による同一レコード識別キーの選択を省略」とは?
「A:B」ボタンをクリックすると下記ダイアログが表示されます。
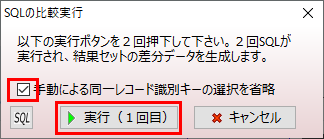
本機能では2つの結果セット(SQLの実行結果)を比較するときに、各行を識別するためのキー(ユニークキー)が必要です。このキーを使ってどのレコードが同一かを特定し、追加・削除・変更を検出します。
通常は、結果セットに含まれる列の中から、識別キー(主キーやユニークな列)を手動で選択する必要がありますが、次のようなケースではその選択が不要になります。
- 結果セットに識別キーが含まれている場合
テーブルに主キー(PRIMARY KEY)またはユニーク制約(UNIQUE)が存在し、それが結果セットに含まれている場合。 - 結果セットの列が完全に一致する場合
比較対象の2つの結果セットのカラム構造とデータ型が完全に一致し、行そのものをキーとして比較できる場合。
今回は上記の両方に該当する為、✔を入れて「実行(1回目)」ボタンをクリックします。これで現状のデータセットが取得され、SQLの実行ボタンが「実行(2回目)」になります。
- 「手動による同一レコード識別キーの選択を省略」を✔した時に表示されるメッセージ
- SQL2回目の実行画面
この画面は実行ボタンをクリックするまで表示されます。

2回目のSQLの実行
書籍在庫テーブルのデータ変更
書籍在庫テーブルを更新するため下記のSQL文を実行します。
-- 書籍在庫数の更新
UPDATE books SET stock = 2 WHERE book_id = 1;
UPDATE books SET stock = 10 WHERE book_id = 3;
INSERT INTO books (title, author, price, stock)
VALUES
('Python入門', '田中 正', 2500,5);
DELETE FROM books WHERE book_id = 2;
-- PostgreSQL入門 在庫数を 2に変更
-- A5:SQL Mk-2の基礎 在庫数を10に変更
-- 'Python入門'を追加
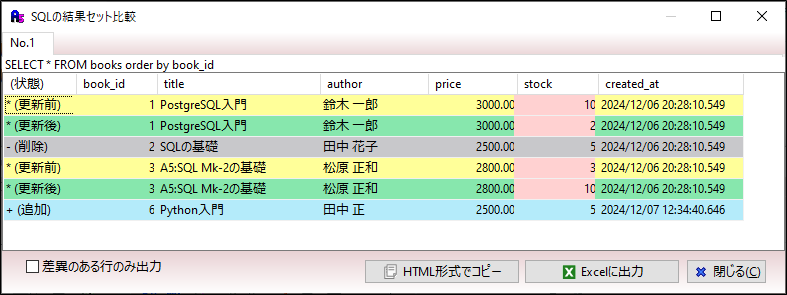
-- 'SQLの基礎を削除'実行結果は以下のようになり、SQL文が正しく書籍在庫テーブルに反映されました。

「書籍在庫テーブル」の変更が確認できたら「SQLの実行2回目」を実行します。そうすると下表のように変更前と変更後のレコードの比較表が表示されます。
まとめ:便利なシーンと効果的な活用法
「SQLを2回実行で結果セットを比較」は、データの変化を視覚的に把握したいときに大変役立つ機能です。特に以下のシーンで活用できます。
- アプリケーションやバッチ処理の検証
- データベースの更新結果の確認
- テスト環境でのトラブルシューティング
手作業での検証が不要になるため、データベース管理者や開発者は業務の時間短縮に繋がります。


